Claude vs ChatGPT: честное сравнение моделей Anthropic и OpenAI
Claude Opus 4.6 против GPT-4.5 и GPT-4o: качество кода, работа с русским языком, extended thinking vs o3, tool use, цены и доступ из России. Разбор без маркетинга.

Anthropic и OpenAI — два главных конкурента на рынке коммерческих LLM. Обе компании выпустили за последний год несколько крупных обновлений: у Anthropic это Claude Opus 4.6 и Sonnet 4.6, у OpenAI — GPT-4.5, GPT-4o и линейка рассуждающих моделей o1/o3. Для российских пользователей выбор между ними осложнён ещё и вопросами доступности.
Мы сравнили обе экосистемы на практических задачах: код, аналитика, творческое письмо, работа с русским языком. Без маркетинговых формулировок — только факты, тесты и цены.
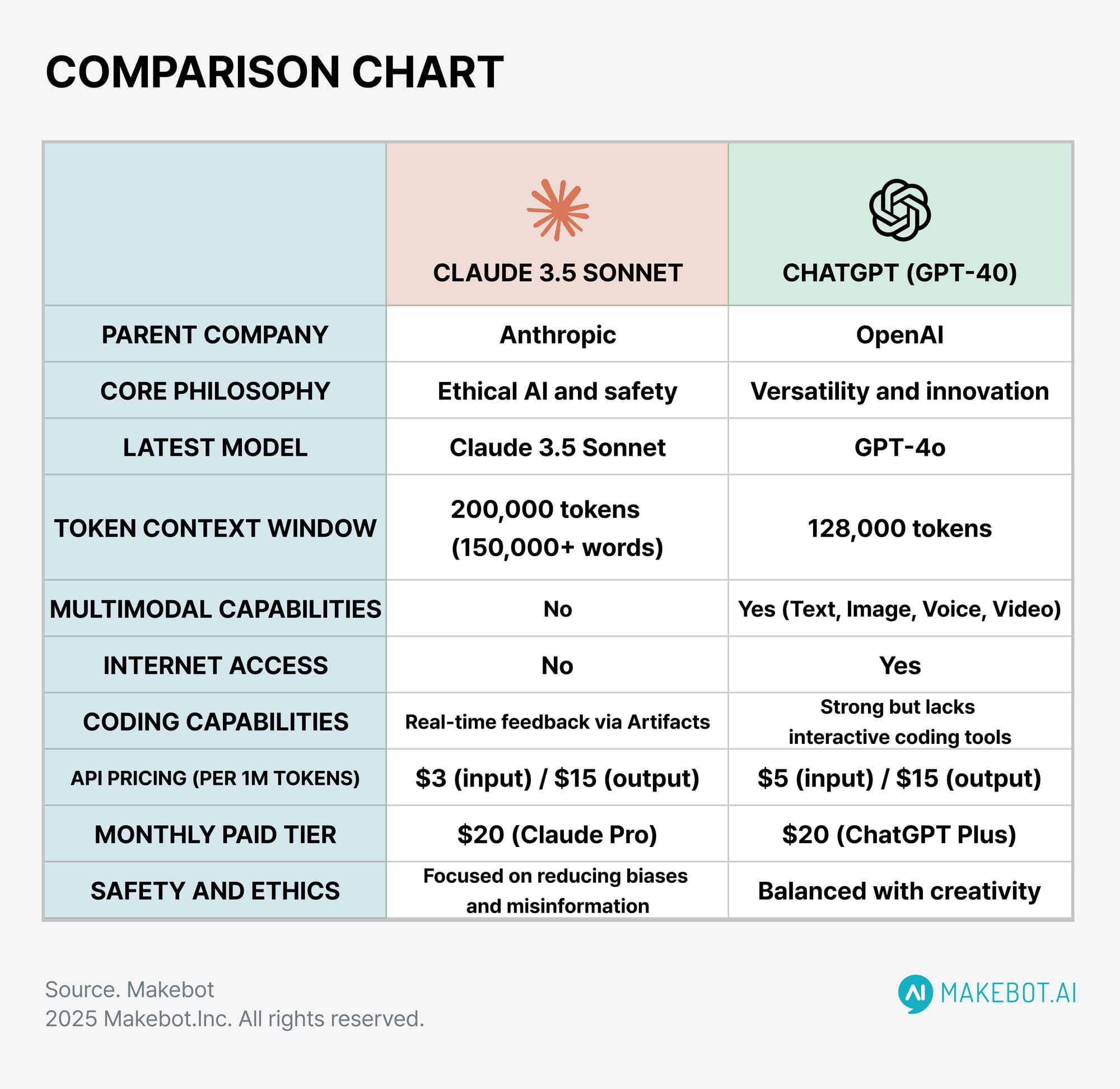
Модельные линейки
Прежде чем сравнивать, стоит разобраться, что с чем сопоставлять. Обе компании предлагают иерархию моделей разного уровня.
| Уровень | Anthropic | OpenAI |
|---|---|---|
| Флагман | Claude Opus 4.6 | GPT-4.5 |
| Основная рабочая | Claude Sonnet 4.6 | GPT-4o |
| Быстрая и дешёвая | Claude Haiku 4.5 | GPT-4o mini |
| Рассуждающие | Claude с extended thinking | o1, o3, o3-mini, o4-mini |
Прямое сопоставление — условность. Claude Opus 4.6 и GPT-4.5 решают разные задачи с разной степенью успешности. Разберём по категориям.
Код
Программирование — область, где разница между Claude и ChatGPT наиболее ощутима. На бенчмарке SWE-bench Verified, который измеряет способность модели исправлять реальные баги в open-source проектах, Claude Opus 4.6 стабильно занимает первое место с результатом более 70%. GPT-4o показывает около 40%, GPT-4.5 — порядка 50%.
На практике это выражается в нескольких вещах:
- Claude лучше понимает контекст большого проекта. Если дать модели несколько связанных файлов и попросить внести изменение, Claude точнее определяет, какие модули затронуты и какие побочные эффекты возможны.
- Claude реже генерирует «почти правильный» код. Типичная проблема GPT-4o — код компилируется, но содержит логическую ошибку или не учитывает граничный случай. Claude допускает такие промахи заметно реже.
- GPT-4o быстрее генерирует бойлерплейт. Для типовых задач — CRUD-эндпоинты, React-компоненты, SQL-запросы — GPT-4o работает быстрее и дешевле при сопоставимом качестве.
Не случайно AI-кодеры вроде Cursor по умолчанию используют модели Claude для агентного режима. Подробнее о работе с Claude через API — в нашем практическом руководстве.
Контекстное окно
Claude поддерживает контекст в 200 000 токенов — это примерно 500 страниц текста или целая кодовая база среднего проекта. У GPT-4o и GPT-4.5 — 128 000 токенов.
Разница в 72 000 токенов существенна при конкретных сценариях:
- Анализ длинных юридических документов или технических спецификаций
- Работа с большой кодовой базой без RAG
- Суммаризация книг и объёмных отчётов за один запрос
Claude также лучше справляется с «needle in a haystack» — поиском конкретного факта в длинном контексте. В тестах на 200K-контексте Claude находит целевую информацию с точностью выше 99%. GPT-4o на своих 128K показывает около 95%, причём качество падает ближе к середине контекста.
Рассуждающие модели: extended thinking vs o1/o3
Оба вендора предлагают режимы «глубокого размышления», когда модель тратит дополнительные вычисления на сложные задачи.
Claude extended thinking — режим, доступный для Opus и Sonnet. Модель генерирует внутреннюю цепочку рассуждений (видимую разработчику через API), а затем формирует финальный ответ. Бюджет на размышления задаётся параметром budget_tokens — от 1024 до 128 000. Чем больше бюджет, тем качественнее ответ на сложных задачах, но и дороже запрос.
OpenAI o1, o3, o4-mini — отдельные модели, специально обученные для рассуждений. Цепочка мышления скрыта (доступен только краткий пересказ). Модели o3 и o4-mini показывают сильные результаты на математических и научных бенчмарках: AIME 2024, GPQA Diamond, Codeforces.
На практике: для кода и инженерных задач extended thinking от Claude часто даёт лучший результат, особенно в контексте большого проекта. Для математики и формальной логики o3 и o4-mini от OpenAI сильнее. Подробнее о техниках работы с обоими подходами — в материале о продвинутом промпт-инжиниринге.
Креативное письмо и аналитика
Claude традиционно сильнее в длинных текстовых задачах: анализ документов, написание отчётов, редактирование. Модель реже скатывается в шаблонные формулировки и лучше держит заданный стиль на протяжении длинного текста.
GPT-4.5, выпущенная OpenAI в феврале 2025 года, заметно улучшила качество творческого письма по сравнению с GPT-4o. Модель стала естественнее, менее «роботной» в открытых задачах. Но на генерации длинных связных текстов (более 2000 слов) Claude по-прежнему стабильнее — GPT-4.5 чаще теряет нить повествования и повторяется.
По аналитическим задачам — анализ данных, выводы из таблиц, сравнение документов — модели близки по качеству. Claude точнее работает с нюансами и оговорками, GPT-4o быстрее даёт структурированный ответ.
Tool use и агентные сценарии
Оба API поддерживают вызов пользовательских функций (tool use / function calling). Но архитектура отличается.
Claude использует нативный tool use с JSON Schema для описания параметров. Модель умеет вызывать несколько инструментов параллельно, корректно обрабатывает ошибки инструментов и может решать задачи итеративно — запрашивая инструменты до тех пор, пока задача не решена. Для агентных сценариев у Anthropic есть протокол MCP (Model Context Protocol) — открытый стандарт интеграции AI с внешними системами.
OpenAI предлагает function calling с аналогичной механикой, а также Assistants API — готовый фреймворк для создания агентов с встроенным управлением контекстом, файлами и инструментами. Плюс — экосистема готовых плагинов и GPTs (кастомные ассистенты в ChatGPT). Минус — привязка к инфраструктуре OpenAI.
По качеству следования инструкциям tool use Claude лидирует: реже галлюцинирует параметры, точнее соблюдает схему, лучше обрабатывает сложные вложенные вызовы. Это подтверждается и бенчмарком Berkeley Function Calling Leaderboard, где Claude Sonnet 4.6 стабильно входит в тройку лидеров.
Качество русского языка
Обе модели генерируют грамотный русский текст — ошибки в орфографии и грамматике редки. Но есть различия.
Claude чаще использует естественные русские конструкции. Предложения строятся с правильным порядком слов, деепричастные обороты используются корректно, стиль выдержан. При этом Claude иногда пропускает специфику российского контекста — например, может не знать деталей свежего законодательства или региональных особенностей.
ChatGPT генерирует чуть более «переводной» русский — встречаются кальки с английского, избыточные пассивные конструкции и канцеляризмы. Зато GPT-4o лучше знает российские реалии: компании, законы, географию. Это объясняется большим объёмом русскоязычных данных в обучающей выборке.
Для сравнения качества на русском языке с отечественной моделью — смотрите наше сравнение YandexGPT и ChatGPT.
Стоимость
| Модель | Input (за 1M токенов) | Output (за 1M токенов) | Подписка (чат) |
|---|---|---|---|
| Claude Opus 4.6 | $15 | $75 | $20/мес (Pro) |
| Claude Sonnet 4.6 | $3 | $15 | $20/мес (Pro) |
| Claude Haiku 4.5 | $0.80 | $4 | Бесплатно (с лимитами) |
| GPT-4.5 | $75 | $150 | $200/мес (Pro) |
| GPT-4o | $2.50 | $10 | $20/мес (Plus) |
| GPT-4o mini | $0.15 | $0.60 | Бесплатно (с лимитами) |
| o3 | $10 | $40 | $20/мес (Plus) / $200/мес (Pro) |
Ключевые наблюдения:
- Claude Sonnet 4.6 — оптимальное соотношение цены и качества для большинства задач. За $3/$15 вы получаете модель, которая на задачах кода и анализа сопоставима с GPT-4o ($2.50/$10), а на многих превосходит.
- GPT-4.5 — самая дорогая модель на рынке. $75 за миллион входных токенов — в 5 раз дороже Claude Opus. Оправдана только для задач, где GPT-4.5 даёт измеримо лучший результат.
- GPT-4o mini — самый дешёвый вариант для высоконагруженных приложений, где допустимо умеренное качество.
Обе компании предлагают prompt caching (кеширование повторяющихся промптов) и batch API для снижения затрат. О выборе между моделями для разных задач подробнее — в гайде по LLM для разработчиков.
Доступность из России
Для российских пользователей это, пожалуй, самый болезненный раздел. Ни Claude, ни ChatGPT официально не работают в России.
| Параметр | Claude | ChatGPT |
|---|---|---|
| Регистрация из России | Заблокирована | Заблокирована |
| Оплата российской картой | Нет | Нет |
| Доступ к API | Нет (официально) | Нет (официально) |
| Мобильное приложение | Через VPN | Через VPN |
| Сложность обхода | Выше (строгая проверка) | Ниже (больше обходных путей) |
ChatGPT доступнее на практике: больше зеркал, посредников и способов регистрации. У Anthropic проверка геолокации строже — Claude чаще блокирует аккаунты при использовании VPN. Для доступа к API Claude из России пользователи обычно используют зарубежные серверы или сервисы-посредники.
Для тех, кому нужна полностью легальная работа с персональными данными в российской юрисдикции, оба варианта не подходят. Стоит рассмотреть YandexGPT или развёртывание открытых моделей на собственных серверах.
Когда выбирать Claude
- Программирование — код-ревью, рефакторинг, написание тестов, агентные IDE
- Работа с длинными документами — 200K контекст позволяет анализировать целые кодовые базы и объёмные отчёты
- Агентные сценарии — надёжный tool use, MCP-интеграции
- Аналитические задачи, требующие глубины: extended thinking с настраиваемым бюджетом
- Редактирование и написание длинных текстов с выдержанным стилем
Когда выбирать ChatGPT
- Мультимодальность — GPT-4o нативно работает с текстом, изображениями и аудио в одном запросе
- Математика и формальная логика — модели o3 и o4-mini сильнее на олимпиадных задачах и научных вопросах
- Экосистема — GPTs, плагины, Assistants API, интеграция с Microsoft 365
- Массовые задачи с низким бюджетом — GPT-4o mini при $0.15/$0.60 за миллион токенов практически вне конкуренции по цене
- Простота доступа из России — больше обходных путей и посредников
Резюме
Claude и ChatGPT — не взаимозаменяемые продукты, а инструменты с разными сильными сторонами. Claude Sonnet 4.6 — лучший выбор для разработчиков, аналитиков и всех, кто работает с длинным контекстом и сложными текстами. GPT-4o — универсальный солдат с мультимодальностью, огромной экосистемой и самой дешёвой mini-моделью на рынке.
Оптимальная стратегия для серьёзных проектов — использовать обе модели для разных задач. Claude для кода и глубокой аналитики, GPT-4o для мультимодальных запросов и массовой обработки. Это не вопрос лояльности к бренду — это вопрос инженерной прагматики.


