Тренды ИИ в 2026 году: что уже сбылось, а что нет
Тренды ИИ 2026: что уже стало нормой, где агенты пока требуют контроля и почему рынок сместился к мультимодальности, open-weight моделям и регулированию.

Проверено 12 мая 2026 года. По запросу «тренды ИИ 2026» обычно ждут либо бесконечный список громких тезисов, либо ещё одно пророчество про «год AGI». Полезнее другой формат: посмотреть, что уже стало рабочей нормой, что дошло до рабочего применения только в узких сценариях, а что рынок за год переоценил.
Эта страница остаётся широкой годовой точкой входа. Если вам нужен отдельный разбор лидеров и цен, открывайте аналитику рынка LLM в 2026 году. Если интересует именно агентный слой, полезнее материал про агентный ИИ. Если спорите между локальным стеком моделей с открытыми весами и закрытым API, идите в разбор открытых моделей против проприетарных. Здесь задача уже другая: понять, какие линии действительно определяют 2026 год.
Коротко: какие тренды ИИ в 2026 уже подтвердились
| Сигнал | Вердикт | Почему это важно |
|---|---|---|
| ИИ встроился в основные интерфейсы | Сбылось | Google уже связывает AI Overviews с ростом использования поиска Google, а Gemini 2.5 описывает мультимодальность как базовый режим, а не редкую функцию |
| Агенты стали рабочим слоем | Частично сбылось | У OpenAI, Anthropic и Google есть реальные агентные продукты, но официальные страницы всё ещё строятся вокруг предварительного доступа, согласования действий и контроля человека |
| Модели с открытыми весами вышли из «запасного» сценария | Сбылось | Qwen3 и Mistral 3 уже выпускают не один экспериментальный релиз, а целые семейства моделей под Apache 2.0 |
| Регулирование стало операционным фактором | Сбылось | У AI Act появились не только принципы, но и конкретные даты для прозрачности и требований к высокорисковым системам |
| Одна универсальная модель закроет всё | Не сбылось | Вендоры расширяют семейства моделей по скорости, цене и задержке, а не сходятся к одному варианту по умолчанию |
1. ИИ вышел из отдельного чат-окна и встроился в интерфейсы
Самый очевидный сбывшийся тренд 2026 года: ИИ перестал жить в отдельной вкладке «поболтать с ботом». Google ещё в мае 2025 года писал, что AI Overviews стали одним из самых успешных запусков в истории поиска Google, а в США и Индии дают более 10% роста использования Google для тех типов запросов, где эти обзоры показываются. Это важный маркер: речь уже не о лабораторной демонстрации, а о том, как пользователи меняют базовый поисковый паттерн.
То же видно по модели взаимодействия. В июньском материале про Gemini 2.5 Google прямо пишет, что Gemini изначально построен как мультимодальная система, которая понимает и генерирует текст, изображения, аудио, видео и код. Другими словами, мультимодальность больше не продают как отдельную вау-функцию. Она стала новым базовым стандартом для сильных систем, особенно там, где ИИ должен не только отвечать, но и слушать, видеть и работать в живом интерфейсе.
Практический вывод простой: спор «нужен ли нам ИИ-интерфейс» уже закончился. Теперь спорят о другом: в каком месте он должен появиться первым. В поиске, в рабочих документах, в поддержке, в IDE, в аналитике. Поэтому тренд 2026 года звучит не как «ИИ победил», а как «ИИ занял место в привычных продуктах».
2. Агенты стали рабочим слоем, но не автономными сотрудниками
Здесь рынок одновременно прав и неправ. Прав в том, что агентный слой уже не выглядит фантазией. OpenAI называет Responses API базовым строительным блоком для агентных приложений и отдельно подчёркивает встроенные инструменты, фоновый режим и работу с внешними системами. Google выпустил Gemini 2.5 Computer Use model как специализированную модель для агентов, которые умеют взаимодействовать с интерфейсами. Anthropic подаёт Claude Code не как автодополнение, а как агентный инструмент для работы с кодом.
Но из этих же официальных описаний видно и ограничение. У Anthropic режим по умолчанию остаётся осторожным: Claude Code спрашивает перед изменением файлов и запуском команд. У Google это всё ещё предварительный доступ через API. У OpenAI основное обещание завязано на инструментах, оркестрации и надёжности, а не на магии «поставил задачу и ушёл». Поэтому честный вердикт для 2026 года такой: агенты уже продаются как рабочий слой, но почти всегда в контролируемом контуре, где человек всё ещё держит право последнего действия.
Это развилка, которую легко пропустить. Шум вокруг «AI agents» создаёт ощущение, будто рынок уже приехал к цифровым сотрудникам общего назначения. Нет. Он приехал к другому: к набору систем, которые закрывают цельный рабочий цикл в одной области. Код, исследования, интерфейсные действия, поиск по знаниям, документооборот. Не всё сразу. Поэтому для глубокого разбора здесь полезнее уже не общая статья про тренды, а отдельный материал про архитектуры и реальные сценарии агентного ИИ.
3. Модели с открытыми весами перестали быть запасным вариантом
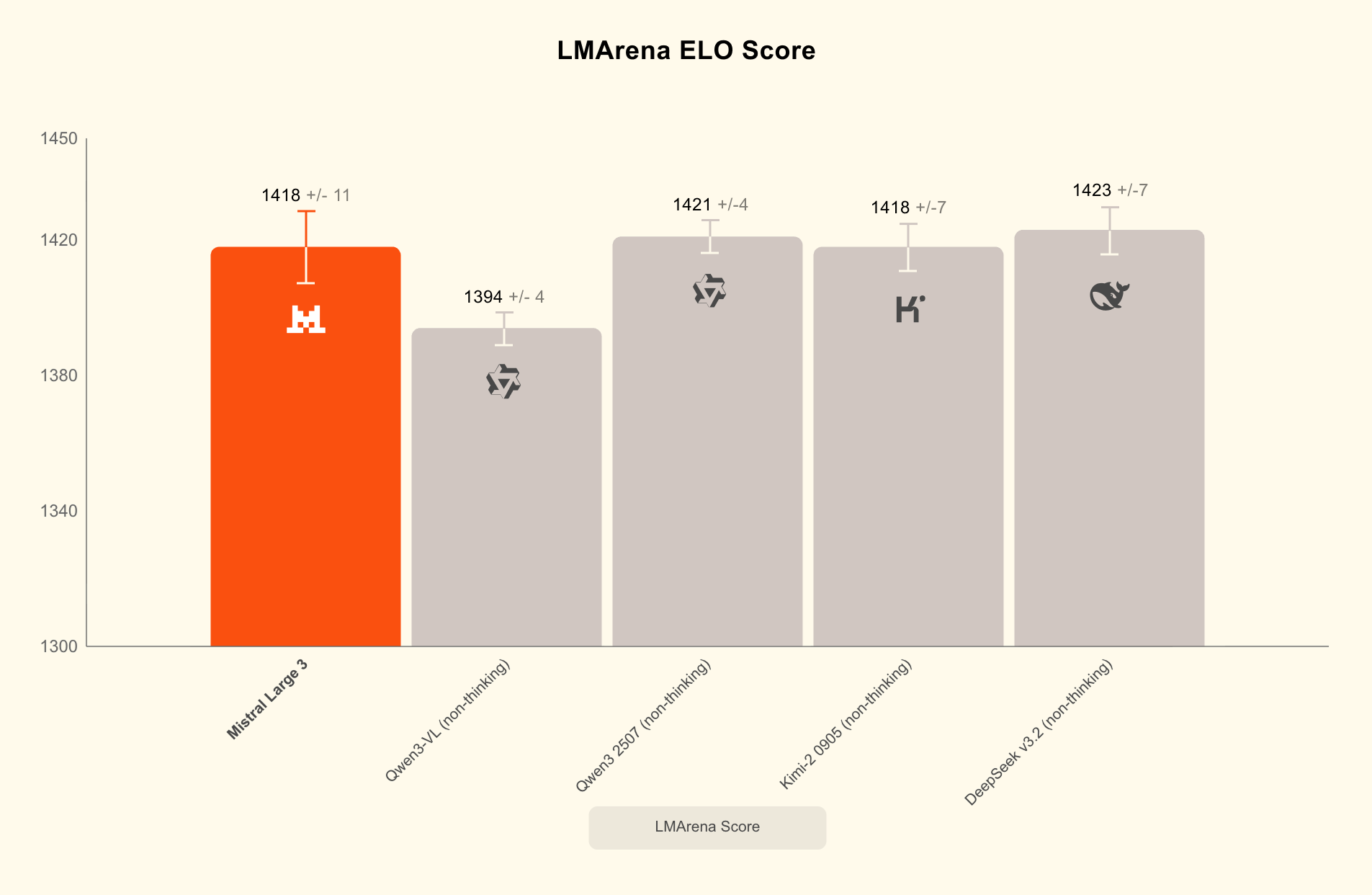
Ещё один сбывшийся тренд 2026 года: стек моделей с открытыми весами больше не обсуждают только энтузиасты или команды с идеологией «никаких закрытых API». На официальной странице Qwen3 команда пишет, что открыла сразу две MoE-модели и шесть плотных моделей под Apache 2.0. В анонсе Mistral 3 компания показывает похожую логику: не один символический релиз, а линейку 14B, 8B и 3B плюс Mistral Large 3, тоже под Apache 2.0.
Это меняет не только технический стек, но и саму точку входа в закупку. Раньше стек с открытыми весами часто был «вариантом Б», если не договорились по бюджету с закрытым провайдером. В 2026 году для многих команд он стал нормальной первой веткой выбора: что идёт в закрытый API, что можно держать локально, где нужен контроль над задержкой, где критичны стоимость, контур хранения данных и предсказуемость. Поэтому модели с открытыми весами перестали быть культурным маркером. Они стали операционным вариантом.
Из этого следует ещё один важный сдвиг. В 2026 году вопрос «открытый или закрытый стек» почти никогда не живёт отдельно от вопроса «какие задачи вообще нельзя держать на одном универсальном провайдере». Поэтому рядом с этим годовым обзором имеет смысл держать под рукой отдельный разбор выбора между открытыми моделями и проприетарными API.
4. Регулирование превратилось из панели на конференции в календарь и чеклист
Если в 2024 и 2025 годах про регулирование часто говорили как о фоне, то в 2026 оно стало частью инженерной и продуктовой рутины. По FAQ Еврокомиссии, разъяснения по Article 50 и связанные обязанности по прозрачности начинают применяться 2 августа 2026 года. Там же зафиксировано, что правила управления и обязанности для ИИ общего назначения действуют с 2 августа 2025 года. Это уже не абстрактный разговор о том, «придут ли правила». Они пришли в виде дат, обязанностей и документов.
Дальше важен второй шаг. В новости Еврокомиссии от 8 мая 2026 года отдельно уточнён график для высокорисковых систем: ряд областей вроде биометрии, критической инфраструктуры, образования и занятости переходит на новые правила с 2 декабря 2027 года, а системы внутри регулируемых продуктов — с 2 августа 2028 года. И это очень характерно для нынешнего этапа рынка: разговор смещается с принципов на последовательность внедрения, стандарты, отчётность и инструменты поддержки.
Для редакционной оценки это означает простую вещь. В 2026 году соответствие требованиям больше нельзя выносить за скобки как тему только для юристов. Оно залезает в закупку, в выбор вендора, в политику логирования, в раскрытие факта контента, созданного или изменённого ИИ, и в требования к документации. Даже если вы не строите высокорисковый продукт, рынок уже двигается туда, где «как это задокументировано» становится частью качества продукта.
5. Не сбылся главный красивый миф: одна модель не закрыла всё
Самый заметный несбывшийся прогноз года не про AGI и не про рынок труда. Он про архитектуру выбора. Идея, что индустрия быстро сойдётся к одной универсальной модели, которая одинаково хорошо решает всё подряд, не подтвердилась. Наоборот, вендоры продолжают дробить линейки. Google в июне 2025 года расширил Gemini 2.5 до Flash, Pro и Flash-Lite и прямо пишет о компромиссе между стоимостью, скоростью и возможностями. Mistral 3 тоже выходит не одной «магической» моделью, а набором размеров и режимов под разные ограничения.
Это, пожалуй, главный практический вывод для второй половины 2026 года. Побеждает не тот, кто нашёл «лучшую модель вообще», а тот, кто настроил нормальную маршрутизацию по задачам: где нужна быстрая дешёвая модель, где большая модель для сложных рассуждений, где развёртывание с открытыми весами, где жёсткий контроль человека, а где решает пропускная способность и стоимость инфраструктуры. Поэтому следующая линия конфликта пройдёт не между названиями моделей, а между системами оркестрации, оценки качества и вычислительным контуром. Именно здесь уже пересекается тема дефицита мощностей, о котором отдельно полезно читать в материале про ограничения ИИ-инфраструктуры.
Что это значит для оставшейся части 2026 года
Если свести весь годовой срез к одному выводу, он будет довольно приземлённым. 2026 год — не про один волшебный прорыв. Он про сборку рабочего ИИ-контура.
- Интерфейсы: ИИ уже встроился в поиск, документы и прикладные среды. Вопрос не «нужен ли», а «куда ставить первым».
- Агенты: рабочий цикл становится полезным, но рынок всё ещё живёт на контроле человека, согласовании действий и явных границах среды.
- Модели: вместо одного победителя формируется портфель: быстрые, рассуждающие, мультимодальные, частные и с открытыми весами.
- Регулирование: соответствие требованиям и маркировку происхождения контента уже нельзя отложить до «потом» без продуктового долга.
Поэтому самый точный способ описать тренды ИИ в 2026 году такой: ИИ окончательно перестал быть темой только для демо и лабораторий. Теперь это слой решений, ограничений и маршрутизации. Скучнее, чем обещания про скорый цифровой суперинтеллект. Но для реального рынка важнее именно это.
Источники
- Google: AI in Search: Going beyond information to intelligence
- Google DeepMind: Gemini 2.5 native audio capabilities
- OpenAI: New tools and features in the Responses API
- Anthropic: Claude Code product page
- Google DeepMind: Gemini 2.5 Computer Use model
- Qwen Team: Qwen3
- Mistral AI: Introducing Mistral 3
- European Commission: Navigating the AI Act
- European Commission: timeline update for AI Act implementation
- Google: Gemini 2.5 model family expands



